
In 1950, Alan Turing, who is considered one of the Fathers of AI, published Computing Machinery and Intelligence in the journal Mind, introducing a fundamental question that has since sparked continuous debate about the future of artificial intelligence: Can machines think? What he proposed, now known as the Turing Test, established an operational criterion of intelligence based on a machine’s ability to sustain a conversation indistinguishable from that of a human. Today, many years later, in 2025, Large Language Models (LLMs) have not only surpassed this test across multiple dimensions and facets, but have also radically redefined our understanding of conversational artificial intelligence.
The current LLM ecosystem showcases an extraordinary variety: from generalist models like GPT-4o and Claude 3.5 Sonnet, to technical specializations such as EXAONE 3.0 by LG AI (indeed, the television and appliance brand has established LG AI Research, which sets AI guidelines across all of the company’s product lines) for scientific research, as well as open-source solutions like LLaMA 3.3 that enable local, customized deployments (to provide greater assurance when working with sensitive or confidential data). This rapid growth has created a complex landscape where the question is no longer Which is the best model to use?, but rather Which is the right model for each specific use case?
On AI Appreciation Month, from Capitole we want to offer you a deep technical perspective on the current LLM ecosystem, evaluating not only the capabilities everyone is already familiar with, but also the persistent limitations (as with any technological solution) and the ethical challenges shaping the future of this transformative technology.
1. The Evolution of LLMs: From Black Boxes to Specialized Toolkits
Until recently, LLMs functioned as true black boxes, meaning that we understood they contained complex systems whose inner workings remained opaque even to their inventors. The transformer architecture, with its trillions of parameters trained on massive datasets, produced astonishing results without us being able to fully explain the “magic” behind these emergent capabilities. This context has drastically changed the rules of the game over the years 2024–2025. Today’s LLMs have evolved into specialized tools with well-documented competencies, clearly identified limitations, and concrete, precisely defined use cases. Industry, as well as the science and technology sectors, have established standardized norms, rigorous evaluation methods, and interpretability frameworks that allow us not only to understand the abilities of these models, but also to manage them and to clarify why they exist.
This evolution is evident in the current ecosystem: although models like GPT-4o maintain their universal versatility, we have seen the emergence of technical specializations such as EXAONE 3.0 for scientific research, Codex for programming, and BioGPT for biomedical applications. According to the 2024 Stanford AI Report, 67% of recent LLM deployments in enterprises have opted for specialized or fine-tuned models rather than general-purpose solutions, representing a fundamental shift in AI adoption strategies.
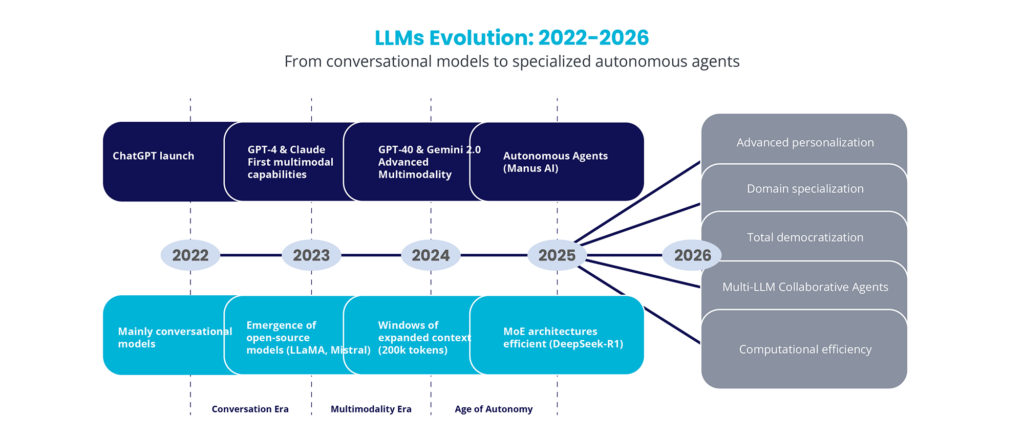
LLMs from 2022 through 2026 have shown us three clearly distinct eras:
The Era of Intelligent Chat (2022–2023) was characterized by the unforgettable arrival of ChatGPT and the first conversational models, followed by the emergence of open-source models such as LLaMA and Mistral.
The Era of Multimodality (2023–2024) introduced the first multimodal capabilities with GPT-4 and Claude, expanding context windows up to 200,000 tokens and creating efficient MoE (Mixture of Experts) architectures such as DeepSeek-R1.
Finally, the Era of Autonomy (2025–2026) marks the shift toward autonomous agents like Manus AI, with accelerating trends toward sophisticated personalization, domain-specific specialization, complete democratization, multi-LLM collaboration agents, and computational optimization.
2. Document Analysis Capabilities: The Case of Claude 3.5 and Extended Context
Document analysis represents one of the most significant challenges in business today. According to the McKinsey Global Institute, approximately 19% of the time knowledge workers spend is dedicated to searching for and gathering information, while reviewing complex documents can require between 40 and 60 hours per week in fields such as law and finance. In highly regulated sectors, such as energy or pharmaceuticals, detailed analysis of regulatory documentation can extend over months, requiring specialized teams and generating considerable operational costs. For example, Claude 3.5 Sonnet, from Anthropic, has transformed this landscape thanks to its vast context window of 200,000 tokens (equivalent to approximately 150,000 words), which enables the handling of complete documents without fragmentation.
Its advanced transformer-based architecture integrates sophisticated attention and memory methods that preserve semantic consistency across long texts, while its multimodal reasoning capabilities facilitate the combined exploration of text, tables, charts, and diagrams within complex documents. In real-world scenarios, Claude 3.5 Sonnet is able to process and analyze documents of up to 500 pages in about 3 minutes, extracting critical information, detecting patterns, and producing structured summaries with an accuracy between 85% and 92%, according to independent benchmarks. Companies such as Klarna have reported a 75% reduction in contract analysis time, while legal organizations indicate savings of 40 to 60 hours per case in regulatory document reviews, transforming workflows that previously required teams of analysts on a weekly basis.
These advances in intelligent document analysis represent a dramatic change in how organizations manage large volumes of information. For example, Claude 3.5 Sonnet is not only increasing operational efficiency but is also democratizing access to complex document analysis that previously required meticulous specialization, making it possible for smaller teams to handle information volumes typically reserved for large corporations. Nevertheless, it remains crucial to acknowledge current limitations such as:
- Accuracy fluctuates depending on the complexity of the domain.
- Processing conclusions may be more relevant for large volumes of data.
- Interpretation of results still requires human oversight to ensure correctness in critical moments.
3. Specialization vs. Versatility: How to Choose the Right LLM for Each Use Case
The arrival of specialized LLMs has fundamentally transformed the paradigm of AI model selection. Although during the 2022–2023 period the main question was Which is the best LLM?, by 2025 the ecosystem requires a more sophisticated perspective: Which is the perfect model for this specific use case? This evolution reflects a maturing market, where differentiation is no longer based solely on broad competencies, but on performance within specific areas, functions, and operational constraints.
Strategic selection of LLMs requires continuous evaluation based on three fundamental dimensions:
- Technical Performance Requirements:
- Operational Parameters:
- Response latency (tokens per second).
- Maximum transaction volume.
- API availability and deployment options (cloud vs. on-premise).
- Financial Criteria:
- Cost per token.
- Total cost of ownership.
- Scalability of pricing.
- Estimated ROI depending on usage volume.
When applying this framework to concrete use cases, clear optimization patterns emerge.
- GPT-4o stands out in multimodal customer interactions in reasoning tasks (MMLU: 87.2%) and visual capabilities, which supports its pricing of $5–9 per million tokens for high-value use cases.
- For document analysis, Claude 3.5 Sonnet optimizes the balance between cost and capability with its 200k-token context window and 89% accuracy in comprehension tasks, priced at $6–12 per million tokens.
- For deployments handling sensitive data, LLaMA 3.3 offers competitive performance (MMLU: 83.6%) with full control over data through local implementation, minimizing recurring expenses after the initial infrastructure investment.
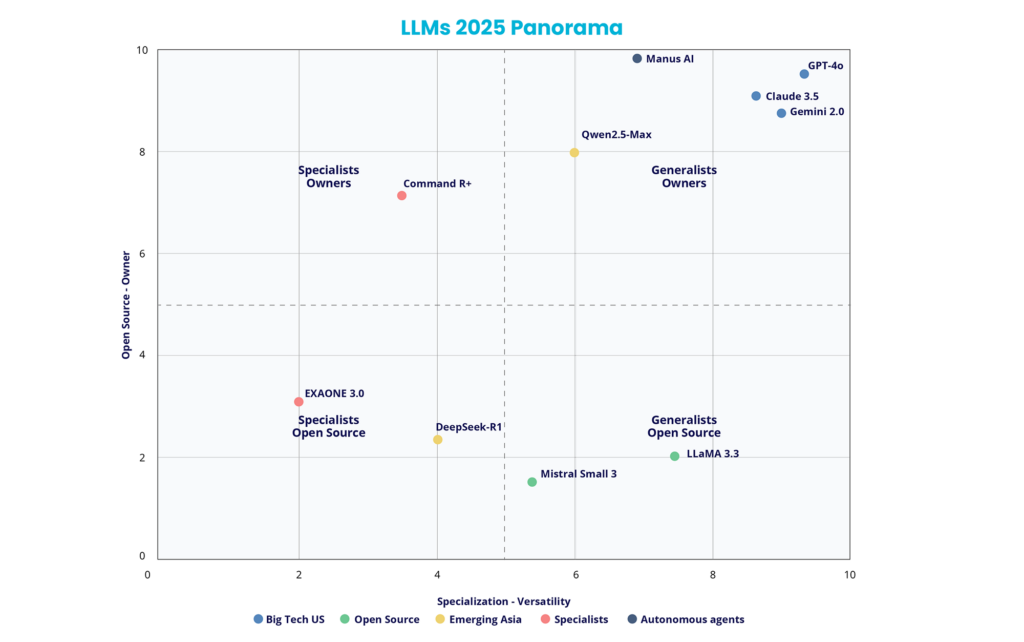
This strategic diversification is clearly evident in the current ecosystem’s competitive positioning. In the previous matrix of specialization versus versatility (horizontal axis) and proprietary models versus open access (vertical axis), four distinctive quadrants emerge:
- The upper-right quadrant hosts unique generalist models such as GPT-4o, Claude 3.5 Sonnet, and Gemini 2.0 Flash, which increase flexibility but require commercially licensed APIs.
- The lower-right quadrant offers versatile open-source alternatives like LLaMA 3.3 and Mistral Large, providing a broad functional spectrum with full control over implementation.
- The upper-left quadrant presents specialized proprietary solutions such as Manus AI for autonomous agents and Command R+ for document analysis, designed for very specific use cases.
- Finally, the lower-left quadrant contains specialized open-access models like EXAONE 3.0 for scientific research and DeepSeek for technical applications, combining specialization with complete transparency.
This segmentation reinforces that the ideal choice is determined both by the specific functional requirements and by the constraints around openness, security, and operational control within the corporate environment.
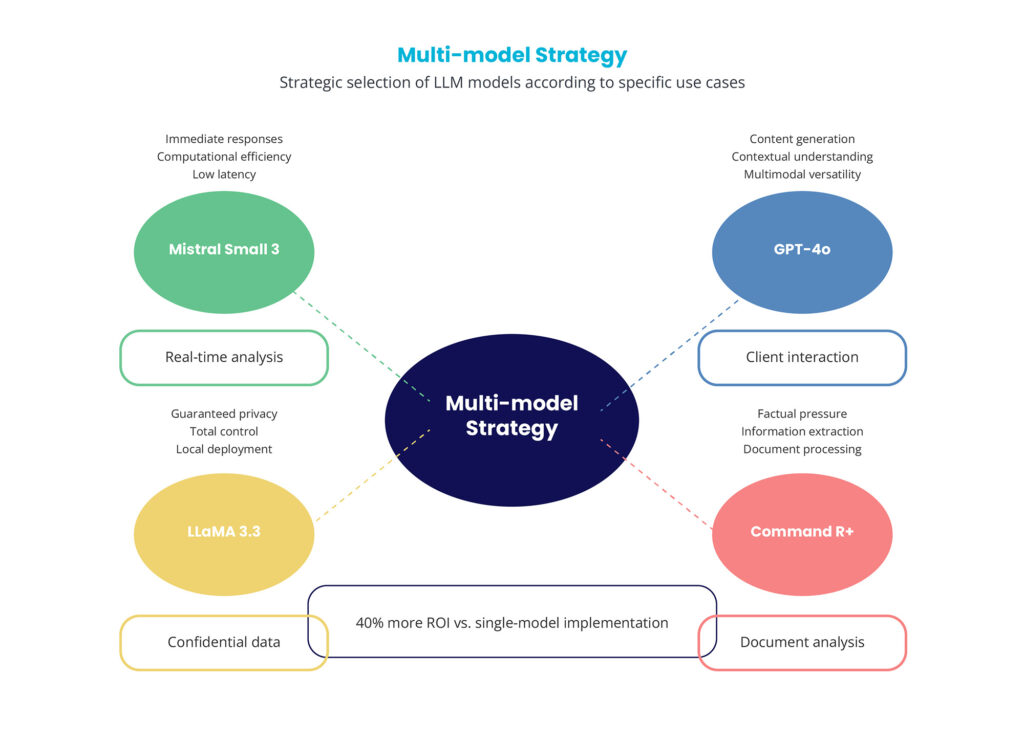
The implementation of this diversification has given rise to tactics involving multiple models that increase companies’ return on investment. Instead of relying on a single universal model, leading organizations are creating specialized ecosystems in which each model is optimized for specific usage scenarios.
For example, as shown in the previous diagram:
- Mistral Small 3 focuses on real-time analysis with computational efficiency, low latency, and immediate responses.
- GPT-4o handles customer interactions through content generation, contextual analysis, and multimodal adaptability.
- LLaMA 3.3 ensures the privacy of sensitive data with full control and on-premise execution.
- Command R+ enhances document analysis with factual accuracy, data extraction, and document handling capabilities.
This multi-model strategy yields 40% more return on investment compared to single-model implementations, demonstrating that strategic specialization surpasses universal versatility in corporate environments.
This evidence-based selection technique requires a structured evaluation process:
- Precisely define the technical, operational, and financial requirements of the specific use case.
- Establish measurable success indicators and minimum performance thresholds.
- Conduct pilot trials with the shortlisted models using datasets that closely replicate the production environment.
- Calculate the projected total cost of ownership over 12–24 months, including integration expenses, team training, and maintenance.
Therefore, the essential principle remains unchanged: strategic optimization outperforms the maximization of general capabilities, and the best choice is always anchored in data-driven analysis of each corporate context.
4. Ecosystem Mapping: Comparative Analysis of Leading LLMs in 2025
In the table below, we have attempted to bring order to the generative AI storm of 2025. You can see:
- The proprietary giants setting the pace in the race.
- The disruptors refining the balance between cost and performance variables.
- And finally, the open-source options that democratize access and data control.
For each model, we display:
- Its MMLU score (the benchmark metric measuring LLM comprehension).
- Price per million tokens.
- And the competitive advantage that makes it stand out for a specific use case.
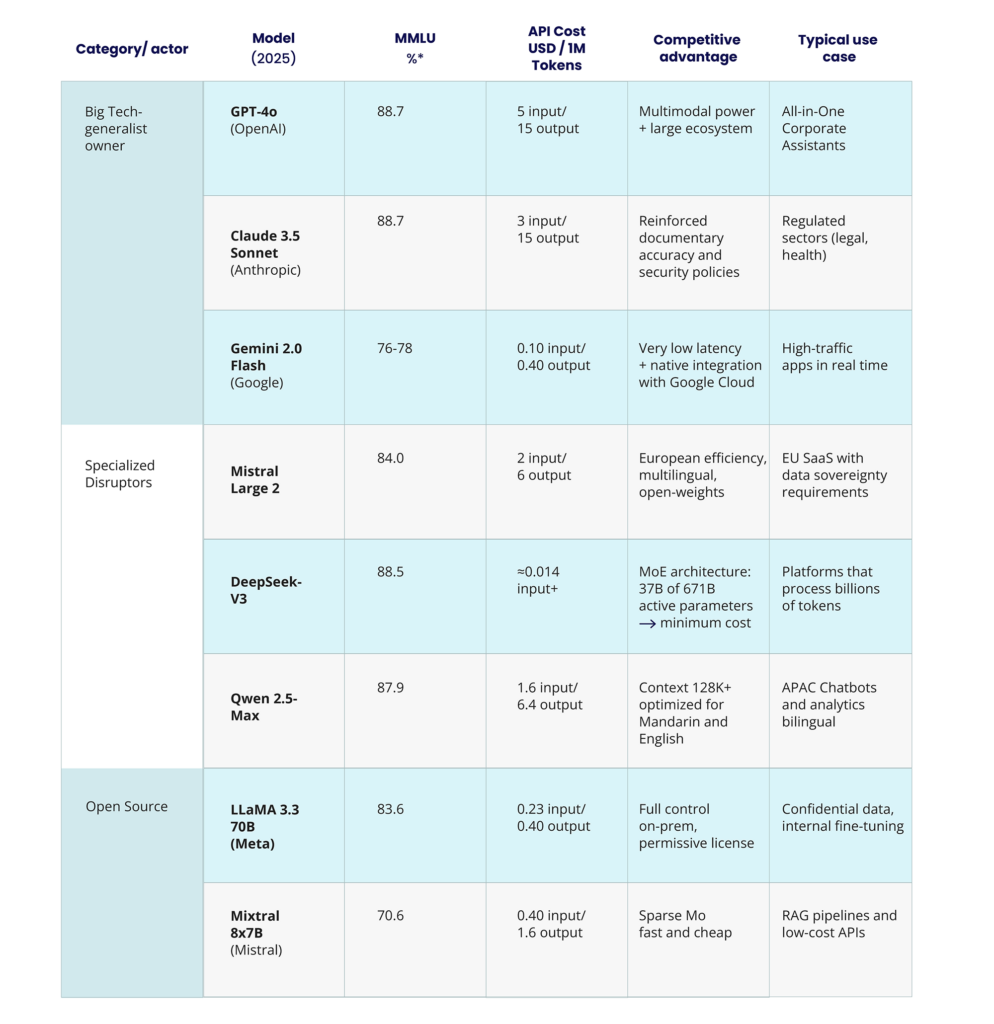
As can be seen in the table, choosing the most suitable LLM is no longer about setting a Guinness record for the highest number of parameters, but about balancing three crucial aspects: actual task performance, operational cost, and business needs.
Therefore, the most effective strategy is usually a multimodal approach: assembling your optimal “battalion” for each specific task. In this way, you can increase ROI, resilience, and iteration speed.
5. Trends 2025–2026: Personalization, Open Source, and Autonomous Agents
Today, the landscape is much clearer, with three key trends, each carrying distinct consequences for business adoption.
Personalization through Fine-tuning and RAG has emerged as the primary driver of competitive differentiation. Companies such as Bloomberg (BloombergGPT), Morgan Stanley (GPT adapted for wealth management), and Salesforce (Einstein GPT) demonstrate that foundational models are only the starting point. The real value lies in adapting them to specific domains: fine-tuning for specialized behaviors and RAG for incorporating proprietary knowledge. According to Forrester 2024, 73% of successful enterprise implementations involve some level of personalization, delivering an average ROI 340% higher than generic deployments.
Vertical specialization is splitting the market into models optimized for particular domains. Qwen 2.5 dominates Asian markets with native cultural understanding, EXAONE 3.0 leads scientific research with 94% accuracy in technical tasks, and Harvey AI specializes in legal services, validated by over 200 companies worldwide. This trend suggests that the future lies in models that choose global versatility within specific areas, creating entry barriers both technical and data-driven.
The democratization of open source is driving convergence in capabilities. LLaMA 3.3 reaches 83.6% on MMLU (compared to 87.2% for GPT-4o), while Mixtral 8x22B rivals proprietary models in targeted tasks. Hugging Face reports over 500 million monthly downloads of open-source models, signaling widespread adoption. This convergence is reducing competitive advantages based solely on tangible technical capabilities and is shifting competition toward ecosystems, services, and horizontal specialization.
The alignment of these trends points to a future where business success in AI will depend less on access to sophisticated models (which are becoming increasingly commoditized) and more on the ability to personalize, specialize, and embed these technologies into concrete workflows. Organizations capable of tailoring base models to their unique contexts will retain enduring competitive advantages.
6. Conclusions: Strategic Implementation of LLMs in the Enterprise
The 2025 LLM landscape has evolved from simply searching for the most capable model to a paradigm of strategic optimization based on specific use cases. This progress demands a structured methodology for business selection and implementation:
Defined decision framework:
Structured analysis based on technical criteria (specific benchmarks), operational parameters (latency, throughput, deployment), and financial considerations (TCO, ROI, scalability) removes subjectivity in model selection. Organizations applying evidence-based techniques will consistently outperform those relying on intuition or market hype.
Specialization as a competitive advantage:
The merging of global capabilities among proprietary and open-source models shifts differentiation toward vertical specialization and personalization. The future belongs to organizations that master fine-tuning, RAG, and the adaptation of base models to singular corporate contexts, generating entry barriers built on data and domain expertise.
Democratization and execution:
Lower technical and financial barriers are making advanced AI capabilities more accessible but are also increasing the importance of implementation strategy. A company’s success will hinge on its ability to integrate LLMs into existing workflows, manage organizational transformation, and cultivate internal AI skills.
At Capitole, we support this transformation by translating technological advances into tangible business value. The LLM revolution is only just beginning, and organizations that adopt strategic, evidence-based approaches focused on specific use cases will lead the next decade of AI innovation.



