
La Inteligencia Artificial Generativa (GenAI) y sus últimos avances están revolucionando el mundo. Según el New York Times se han invertido más de 56 billones de dólares en Startups relacionadas con Gen AI. Esta cifra muestra la apuesta de los grandes inversores en el mundo por esta tecnología. Además, La Curva Gartner que muestra la madurez, adopción y aplicación de tecnologías emergentes, colocaba a la tecnología de la IA Generativa, en el Pico de Expectativas Sobredimensionadas, evidenciando así la cantidad de expectación que existe hoy en día por esta tecnología.
Pero ¿qué es exactamente un LLM? ¿Cómo funciona esta tecnología y cuáles son sus limitaciones? ¿Qué usos tiene esta tecnología en el mundo de la empresa? En el siguiente artículo vamos a dar respuestas a estas preguntas:
¿Qué es exactamente un Large Language Model ?
Un LLM es un modelo de lenguaje natural formados por redes neuronales profundas. Sus redes neuronales se han entrenado con grandes cantidades de datos.
La aplicación al lenguaje natural de modelos estadísticos y de predicción no es algo nuevo.
En los años 80 y 90 con los n-gramas y los modelos ocultos de Markov se desarollo la aplicación de matemática probabilística al lenguaje, dando lugar a una variedad de herramientas y métodos para crear modelos matemáticos más flexibles basados en datos.
Pero no ha sido hasta hace poco cuando sea ha consolidado verdaderamente esta tecnología con el descubrimiento del Transformer por expertos de Google, presentado en el famoso paper “Attention is all you need”, El Transformer es una red neuronal que intenta imitar la atención que ponemos los humanos al contexto de una palabra o conjunto de palabras en un cuerpo de texto. Vamos a verlo con un ejemplo:

Al leer el párrafo anterior establecemos una relación entre las palabras coco – perro – patas – jugar. Si sólo leemos la última frase (A Coco le gusta jugar al pilla-pilla), no sabemos si Coco es un perro o una persona. Sin embargo, gracias a nuestra capacidad de atención tenemos en cuenta el contexto del párrafo completo. Así es como el Transformer calcula las relevancias entre las diferentes palabras de un texto.
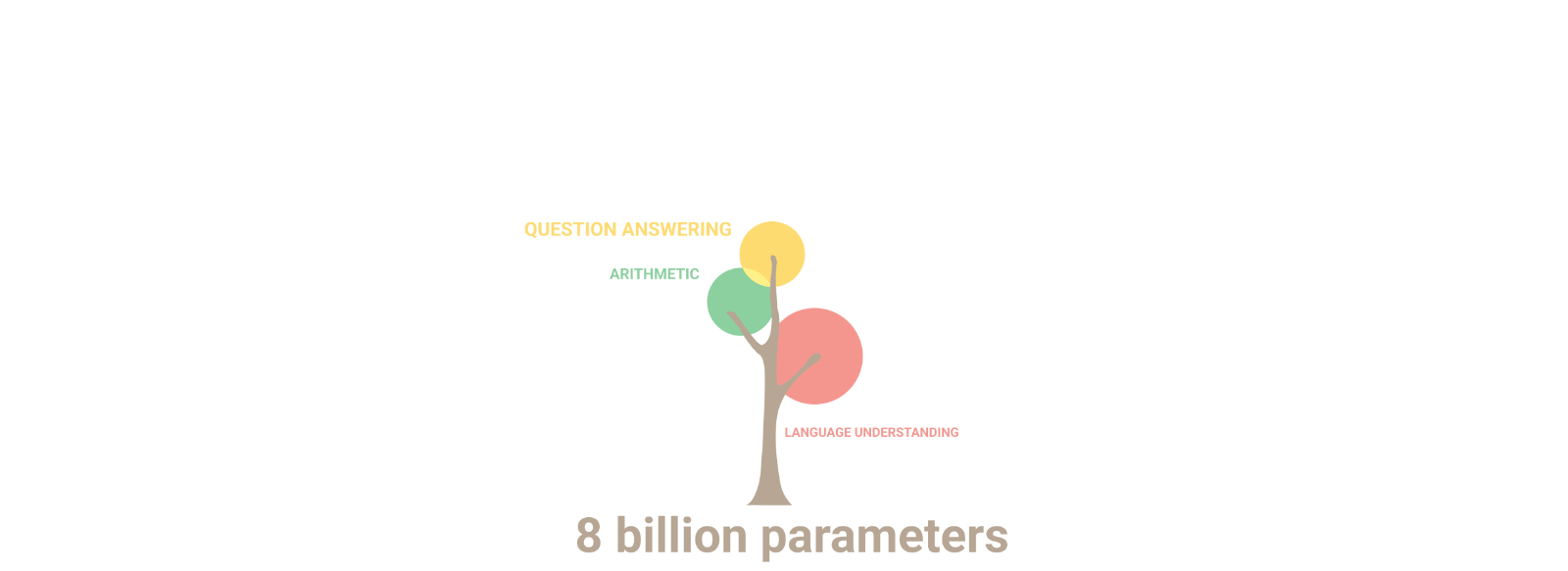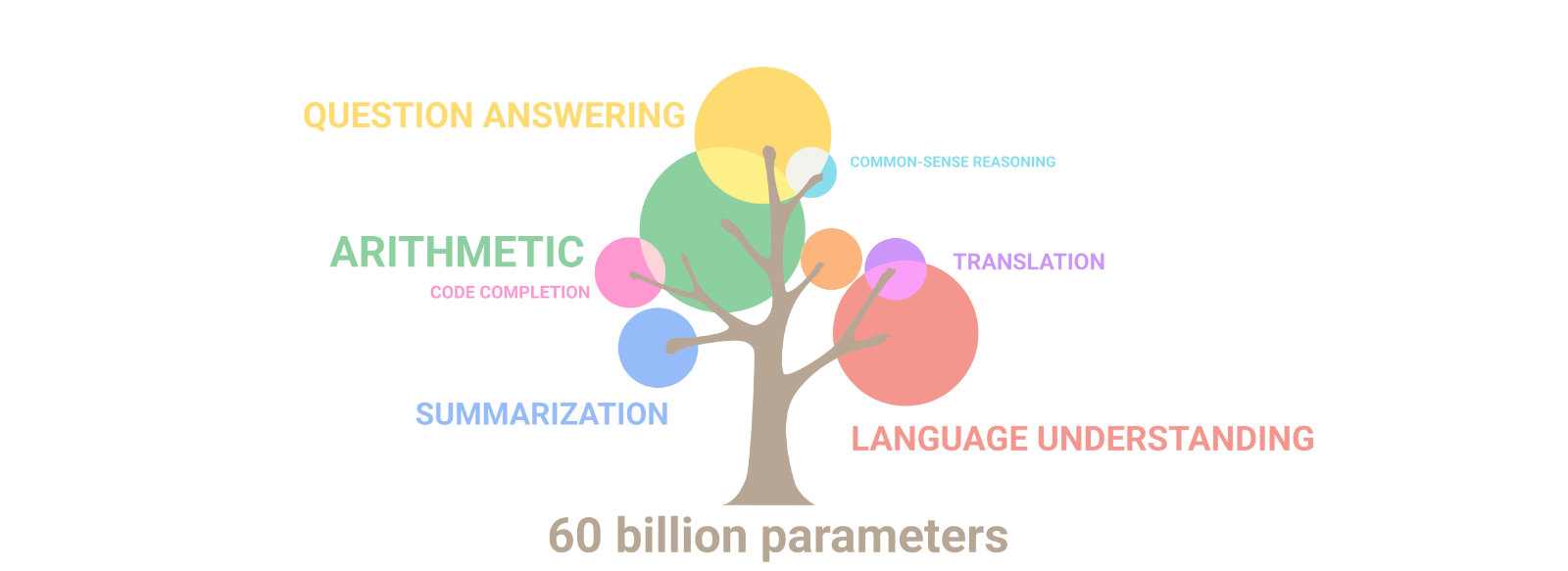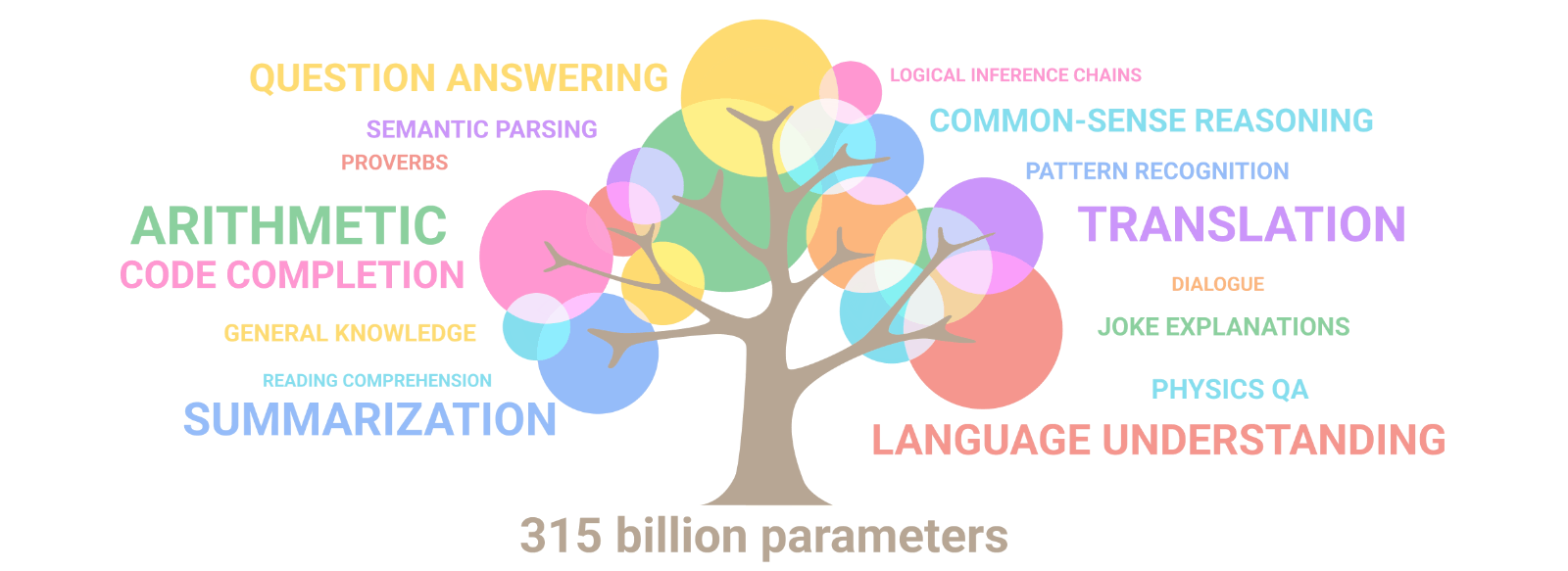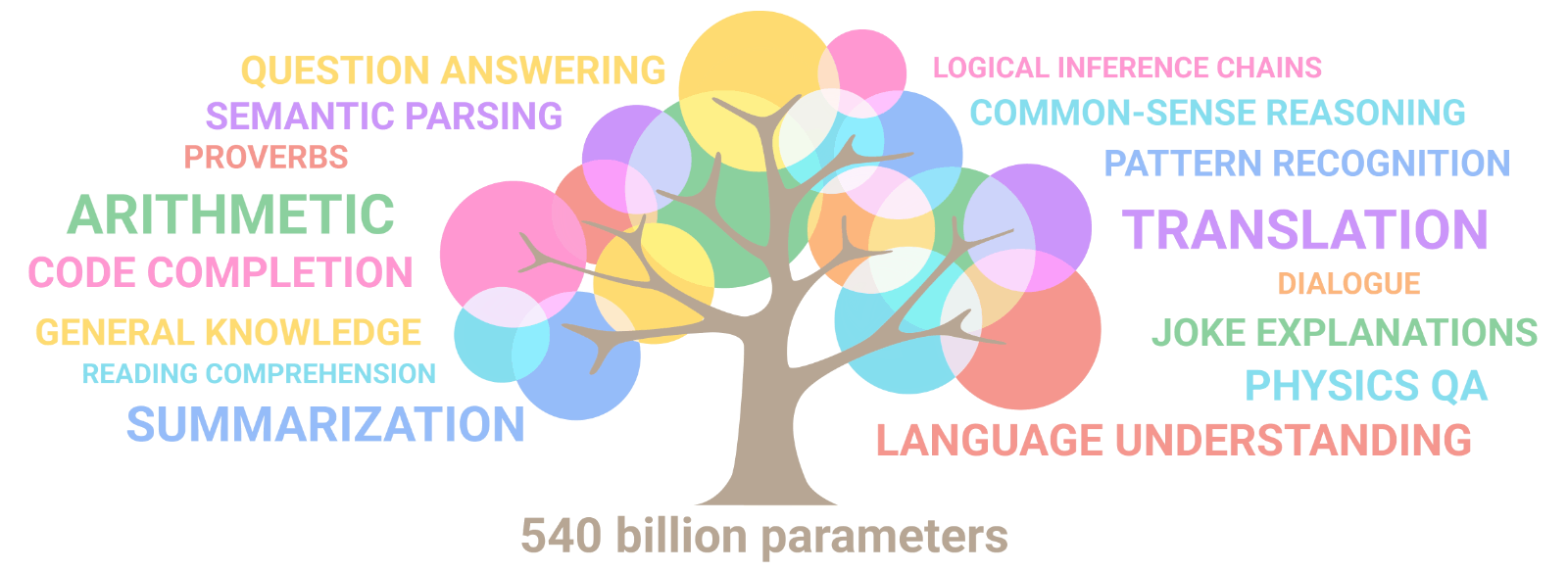
Este descubrimiento dio paso a ChatGPT3, un chatbot basado en el modelo fundacional Generation Pretrained Model 3 (GPT-3) que revolucionó al mundo, convirtiéndose en el chatbot con más crecimiento de usuario activos de la historia. Compuesto por una red neuronal con 175 mil millones de parámetros, es capaz de generar texto, entender el lenguaje y responder a preguntas de manera sorprendente.
Estas capacidades como la comprensión lectora, inferencia lógica o incluso tareas más avanzadas para una máquina, por ejemplo, explicar por qué un chiste es gracioso, estarían al alcance de los modelos más densos.
¿Significa esto el fin para los seres humanos? ¿Acaso la IA nos quitará nuestros trabajos ya que todo podrá ser automatizado por estos modelos?. Aún no, opina el Chief AI Scientist de Meta, de los líderes de opinión Yann Lecun en esta entrevista; los LLMs tienen varias limitaciones que les hacen poco fiables si no van acompañados de las necesarias arquitecturas de software.
¿Cuáles son sus limitaciones?
Una de las mayores limitaciones que tienen los LLMs es que no son capaces de generar datos que estén fuera del set de entrenamiento. Por ejemplo, si preguntas a ChatGPT quien es Steve Jobs, te sabrá contestar quién es el famoso empresario. Sin embargo, si le preguntas sobre las últimas ventas que se han realizado en el departamento comercial de tu empresa, no será capaz de darte una respuesta acertada. Esto ocurre porque los LLMs no tienen acceso directo a la información más actualizada que ocurre en el mundo.
Pero si a estos Chatbots, conectados con LLMs, les damos acceso al contexto adecuado, serían capaces de responder acertadamente a cualquier tipo de pregunta gracias a su poder de redacción y comprensión lingüística.
Es por ello que recientemente ha surgido una nueva arquitectura de software que consigue resolver el problema antes mencionado. Se llama Retrieval Augmented Generation (RAG) y conecta una base de datos con un motor de búsqueda que contiene todo lo relevante para el usuario. De esta forma el LLM podrá tener acceso a la información en la que no fue entrenado.
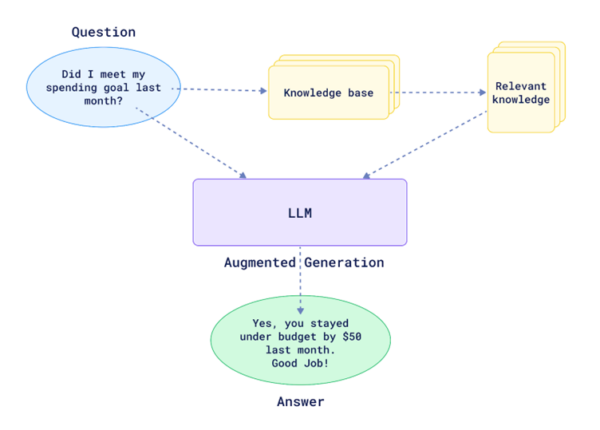
Esto convierte el problema de la falta de contexto de los LLMs en un problema de gestión y búsqueda de la información, cuyas soluciones llevan tiempo estudiándose y desarrollándose en el sector de la información.
La infraestructura que describe una arquitectura RAG esta normalmente formada por:
- Un pipeline de ingesta de datos, o Ingestion Pipeline que inyecta y fragmenta los documentos en diferente partes, comúnmente denominadas chunks. Este pipeline nos ayudará a implementar diferentes estrategias de fragmentado de documentos dependiendo de los datos que contengan.
- El pipeline conectará con un embedding model o modelo de encaje léxico para vectorizar o des vectorizar los datos de entrada y salida de la base de datos. Estos modelos convierten los fragmentos de documentos en representaciones numéricas sofisticadas.
- Por último, una base de datos vectorial, que almacena e indexa la información para su posterior recuperación. La métrica más común para buscar y responder de forma acertada a las consultas del usuario es mediante la similitud coseno.
Por lo tanto, al basar las respuestas en datos actualizados, RAG reduce las posibilidades de generar información incorrecta en forma de alucinaciones, por la tendencia que tienen a responder siempre a las preguntas. Además, se podría investigar hacer fine-tuning o reentreno del modelo para áreas de conocimiento específico (como podría ser apps con conocimiento de prácticas mineras o logística de productos de moda). Actualizar la base de datos puede ser suficiente en casos de uso generales pero existe literatura científica que indican que el fine-tuning del LLM puede aumentar la precisión de la aplicación potenciada con RAG.
Sin embargo, también es importante identificar algunas desventajas:
- La eficacia de la arquitectura RAG depende en gran medida de la calidad de la configuración del motor de búsqueda, así como de una buena estrategia de preprocesamiento de documentos: elegir el modelo de embedding correcto.
- El mensaje contextual de los LLMs es limitado: la cantidad de texto con instrucciones y ejemplos prácticos para que la IA lleve a cabo su función. De acuerdo con la literatura científica cuando el tamaño del contexto aumenta, la capacidad de atención a las acciones que llevan a cabo los modelos disminuye. Por lo tanto, tendremos que redactar los mensajes siguiendo las recomendaciones expertas de prompt engineering para asegurarnos de que todo es interpretado y nada se escapa a la atención del LLM.
- Existe una notable dificultad de evaluación: evaluar una aplicación RAG es difícil debido a la naturaleza no determinista o aleatoria de los LLMs que hace que la calidad de la información generada sea variable si la aplicación no es ajustada correctamente. Ante la dificultad para aplicar métricas tradicionales, se requiere de una continua evaluación y monitorización de estas aplicaciones.
En conclusión, la combinación de Large Language Models (LLMs) con la arquitectura de Retrieval-Augmented Generation (RAG) ha marcado un avance en el área de Natural Language Processing mitigando algunas de las limitaciones clave de los LLMs, como por ejemplo las alucinaciones y el acceso a información actualizada. RAG mejora la precisión de los LLMs al integrar un motor de búsqueda, sin necesidad de incurrir en costes de reentrenamiento del LLM. Sin embargo, el éxito de esta solución depende de la robustez del motor de búsqueda de la base de datos vectorial y la disponibilidad de información relevante.
Los LLMs pueden automatizar tareas repetitivas, mejorar la atención al cliente y facilitar la creación de contenido, permitiendo a tu equipo enfocarse en decisiones estratégicas. No obstante, no todas las tareas se benefician de los LLMs. Para análisis profundos o decisiones basadas en datos muy específicos, RAG puede complementar el modelo proporcionando un contexto actualizado.
Si quieres saber más acerca de cómo estas tecnologías pueden transformar tu negocio, contacta con nosotros en Capitole. Nuestro equipo te ayudará a identificar las aplicaciones más efectivas para optimizar tu operación diaria y aprovechar al máximo la inteligencia artificial, así como desarrollar modelos predictivos.



